5.9. 展望未来:当今的 CPU
CPU 流水线是指令级并行 (ILP) 的一个示例,其中 CPU 同时并行执行多个指令。在流水线执行中,CPU 通过在流水线中重叠执行来同时执行多个指令。简单的流水线 CPU 可以实现 1 的 CPI,每个时钟周期完成一条指令的执行。现代微处理器通常采用流水线和其他 ILP 技术,并包含多个 CPU 核心来实现小于 1 的处理器 CPI 值。对于这些微架构,平均每周期指令数 (IPC) 是通常用于描述其性能的指标。较大的 IPC 值表示处理器实现了高持续程度的同时指令执行。
晶体管是集成电路(芯片)上所有电路的构建块。现代 CPU 的处理和控制单元由电路构成,而电路则由使用晶体管实现的子电路和基本逻辑门构成。晶体管还实现了 CPU 寄存器和快速片上高速缓存中使用的存储电路,用于存储最近访问的数据和指令的副本(我们将在 第 11 章 中详细讨论高速缓存)。
芯片上可容纳的晶体管数量是衡量芯片性能的粗略标准。摩尔定律是戈登·摩尔于 1975 年提出的观察结果,即每个集成电路上的晶体管数量大约每两年翻一番1,2。每两年每个芯片上的晶体管数量翻一番意味着计算机架构师可以设计出一种新芯片,其存储和计算电路空间增加一倍,功率大约增加一倍。从历史上看,计算机架构师使用额外的晶体管来设计更复杂的单处理器,并使用 ILP 技术来提高整体性能。
5.9.1. 指令级并行
指令级并行 (ILP) 是指一组设计技术,用于支持在单个处理器上并行执行单个程序的指令。ILP 技术对程序员来说是透明的,这意味着程序员编写一个顺序 C 程序,但处理器在一个或多个执行单元上同时并行执行其多条指令。流水线是 ILP 的一个示例,其中程序指令序列同时执行,每条指令都在不同的流水线阶段中执行。流水线处理器每个周期可以执行一条指令(可以实现 1 的 IPC)。其他类型的微处理器 ILP 设计可以在每个时钟周期执行多条指令,并实现高于 1 的 IPC 值。
矢量处理器 是一种通过特殊矢量指令实现 ILP 的架构,这些矢量指令以一维数据数组(矢量)作为操作数。矢量指令由矢量处理器在多个执行单元上并行执行,每个执行单元对其矢量操作数的单个元素执行算术运算。过去,矢量处理器通常用于大型并行计算机。1976 年的 Cray-1 是第一台基于矢量处理器的超级计算机,Cray 在整个 20 世纪 90 年代继续使用矢量处理器设计超级计算机。然而,这种设计最终无法与其他并行超级计算机设计竞争,如今矢量处理器主要出现在加速器设备中,例如图形处理单元 (GPU),这些设备特别针对对存储在一维数组中的图像数据执行计算进行了优化。
超标量是 ILP 处理器设计的另一个示例。超标量处理器是具有多个执行单元和多个执行流水线的单个处理器。超标量处理器从顺序程序的指令流中获取一组指令,并将它们分解为多个独立的指令流,由其执行单元并行执行。超标量处理器是一种无序处理器,即执行指令的顺序与指令在顺序指令流中的出现顺序不符。无序执行需要识别可以安全并行执行的没有依赖关系的指令序列。超标量处理器包含动态创建多个独立指令流以通过其多个执行单元的功能。此功能必须执行依赖性分析,以确保任何指令的执行都依赖于这些顺序流中前一条指令的结果,其顺序正确。例如,具有五个流水线执行单元的超标量处理器可以在一个周期内执行来自顺序程序的五条指令(可以实现 5 的 IPC)。然而,由于指令依赖性,超标量处理器并不总是能够保持所有流水线都处于满负荷状态。
超长指令字 (VLIW) 是另一种类似于超标量的 ILP 微架构设计。然而,在 VLIW 架构中,编译器负责构建由处理器并行执行的多个独立指令流。VLIW 架构的编译器会分析程序指令,以静态构建由多条指令组成的 VLIW 指令,每个独立指令流各一条。VLIW 的处理器设计比超标量更简单,因为 VLIW 处理器不需要执行依赖性分析来构建多个独立指令流作为其执行程序指令的一部分。相反,VLIW 处理器只需要添加电路来获取下一个 VLIW 指令并将其分解为多条指令,然后将其输入到每个执行管道中。但是,通过将依赖性分析推送到编译器,VLIW 架构需要专门的编译器才能实现良好的性能。
超标量和 VLIW 都存在一个问题,即并行性能的程度通常受到它们执行的顺序应用程序的严重限制。程序中指令之间的依赖关系限制了保持所有流水线满负荷的能力。
5.9.2. 多核和硬件多线程
通过设计采用日益复杂的 ILP 技术的单个处理器并提高 CPU 时钟速度来驱动日益复杂的功能,计算机架构师设计出的处理器的性能直到 21 世纪初都与摩尔定律保持同步。在此之后,如果不大幅增加处理器的功耗,CPU 时钟速度就无法再提高3。这导致了当前多核和多线程微架构时代的到来,这两者都需要程序员进行 显式并行编程 来加快单个程序的执行速度。
硬件多线程 是一种支持执行多个硬件线程的单处理器设计。线程 是独立的执行流。例如,两个正在运行的程序各自都有自己的独立执行线程。然后,操作系统可以调度这两个程序的执行线程在多线程处理器上“同时”运行。硬件多线程可以通过处理器在每个周期交替执行来自其每个线程的指令流的指令来实现。在这种情况下,不同硬件线程的指令并不是每个周期都同时执行。相反,处理器被设计为在执行来自不同线程的执行流的指令之间快速切换。与在单线程处理器上执行相比,这通常会导致它们整体的执行速度加快。
多线程可以在标量或超标量类型微处理器的硬件中实现。至少,硬件需要支持从多个单独的指令流(每个执行线程一个)获取指令,并为每个线程的执行流提供单独的寄存器集。这些架构显式多线程4,因为与超标量架构不同,每个执行流都由操作系统独立调度,以运行单独的程序指令逻辑序列。多个执行流可以来自多个顺序程序,也可以来自单个多线程并行程序的多个软件线程(我们在第 14 章中讨论多线程并行编程)。
基于超标量处理器的硬件多线程微架构具有多个流水线和多个执行单元,因此它们可以同时并行执行来自多个硬件线程的指令,从而导致 IPC 值大于 1。基于简单标量处理器的多线程架构实现交错多线程。这些微架构通常共享一个流水线,并且始终共享处理器的单个 ALU(CPU 在 ALU 上切换执行不同线程)。这种类型的多线程无法实现大于 1 的 IPC 值。基于超标量的微架构支持的硬件线程通常称为同步多线程 (SMT)4。不幸的是,SMT 通常用于指代两种类型的硬件多线程,仅凭这个术语并不总是足以确定多线程微架构是实现真正的同步多线程还是交错多线程。
多核处理器 包含多个完整的 CPU 核心。与多线程处理器一样,每个核心都由操作系统独立调度。但是,多核处理器的每个核心都是一个完整的 CPU 核心,包含自己完整且独立的功能来执行程序指令。多核处理器包含这些 CPU 核心的副本,并为核心提供一些额外的硬件支持,以共享缓存数据。多核处理器的每个核心都可以是标量、超标量或硬件多线程的。图 1 展示了多核计算机的一个例子。
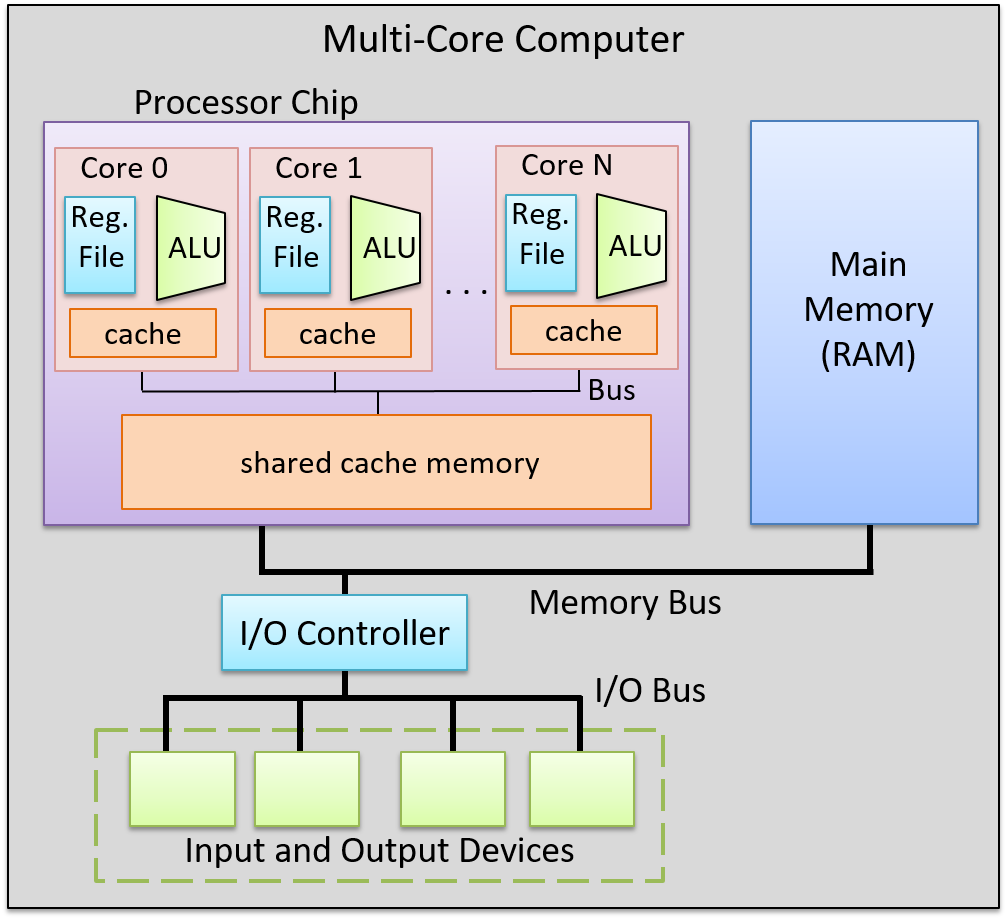
图 1. 带有多核处理器的计算机。处理器包含多个完整的 CPU 内核,每个内核都有自己的专用缓存。内核之间通过片上总线进行通信,并共享更大的共享缓存。
多核微处理器设计是处理器架构性能在不提高处理器时钟频率的情况下继续与摩尔定律保持同步的主要方式。多核计算机可以同时运行多个顺序程序,操作系统使用不同程序的指令流调度每个内核。如果程序编写为显式多线程(软件级线程)并行程序,则可以加快单个程序的执行速度。例如,操作系统可以调度单个程序的线程在多核处理器的各个内核上同时运行,与执行同一程序的顺序版本相比,可以加快程序的执行速度。在第 14 章中,我们讨论了多核和其他类型的具有共享主内存的并行系统的显式多线程并行编程。
5.9.3. 一些示例处理器
如今,处理器是使用 ILP、硬件多线程和多核技术混合构建的。事实上,很难找到非多核的处理器。桌面级处理器通常有 2 到 8 个内核,其中许多内核还支持低级别的每核多线程。例如,AMD Zen 多核处理器5 和英特尔的超线程多核 Xeon 和 Core 处理器6 都支持每核两个硬件线程。英特尔的超线程内核实现了交错多线程。因此,其每个内核只能实现 1 的 IPC,但如果每个芯片有多个 CPU 内核,处理器可以实现更高的 IPC 级别。
为高端系统设计的处理器(例如用于服务器和超级计算机的处理器)包含许多内核,每个内核都具有高度的多线程。例如,用于高端服务器的 Oracle SPARC M7 处理器7 有 32 个内核。每个内核都有八个硬件线程,其中两个可以同时执行,从而使处理器的最大 IPC 值为 64。世界上最快的两台超级计算机(截至 2019 年 6 月)8 使用 IBM 的 Power 9 处理器9。Power 9 处理器每个芯片最多有 24 个内核,每个内核支持最多八路同时多线程。24 核版本的 Power 9 处理器可以实现 192 的 IPC。
脚注和参考文献
- Moore first observed a doubling every year in 1965, that he then updated in 1975 to every > 2 years, which became known as Moore’s Law.
- Moore’s Law held until around 2012 when improvements in transistor density began to slow. Moore predicted the end of Moore’s Law in the mid 2020s.
- “The End of Dennard scaling” by Adrian McMenamin, 2013. https://cartesianproduct.wordpress.com/2013/04/15/the-end-of-dennard-scaling/
- “A Survey of Processors with Explicit Multithreading”, by Ungerer, Robic, and Silc. In ACM Computing Surveys, Vol. 35, No. 1, March 2003, pp. 29–63. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.96.9105&rep=rep1&type=pdf
- AMD’s Zen Architectures: https://www.amd.com/en/technologies/zen-core
- Intel’s Xeon and Core processors with Hyper-Threading: https://www.intel.com/content/www/us/en/architecture-and-technology/hyper-threading/hyper-threading-technology.html
- Oracle’s SPARC M7 Processor: http://www.oracle.com/us/products/servers-storage/sparc-m7-processor-ds-2687041.pdf
- Top 500 Lists: https://www.top500.org/lists/top500/
- IBM’s Power 9 Processor: https://www.ibm.com/it-infrastructure/power/power9